数据
0. 数据转换
tendorflow的操作会自动把numpy的narray变为tenfor;
numpy的操作会自动把tensor变为numpy narray
0.1 手动转换
.numpy()会把tensor转为numpy(会在宿主机和GPU中复制)
0.2 迭代
tf.data.Dataset支持迭代;
1. 创建Dataset对象
The Dataset object is a Python iterable. 可以对dataset迭代;
1.1 从 Numpy arrays中创建
train, test = tf.keras.datasets.fashion_mnist.load_data()
images, labels = train
images = images/255
dataset = tf.data.Dataset.from_tensor_slices((images, labels))
1.2 Python generators
The Dataset.from_generator constructor converts the python generator to a fully functional tf.data.Dataset
def count(stop):
i = 0
while i<stop:
yield i
i += 1
ds_counter = tf.data.Dataset.from_generator(count, args=[25], output_types=tf.int32, output_shapes = (), )
for count_batch in ds_counter.repeat().batch(10).take(10):
print(count_batch.numpy())
结果是:
[0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24] [0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 0 1 2 3 4] [ 5 6 7 8 9 10 11 12 13 14] [15 16 17 18 19 20 21 22 23 24]
1.3 TFRecord data
1.4 loading text
1.5 CSV data
1.6 sets of files
或者对dataset做求和、求平均等操作。
2. 数据操作
2.1 batch
batch操作把数据集中连续的n个元素堆叠成一个element,其操作和tf.stack()很像。
2.2 training workflows
process multiple epochs of the same data.
- use the
Dataset.repeat()transformation
titanic_file = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic_lines = tf.data.TextLineDataset(titanic_file)
def plot_batch_sizes(ds):
batch_sizes = [batch.shape[0] for batch in ds]
plt.bar(range(len(batch_sizes)), batch_sizes)
plt.xlabel('Batch number')
plt.ylabel('Batch size')
titanic_batches = titanic_lines.repeat(3).batch(128)
plot_batch_sizes(titanic_batches)
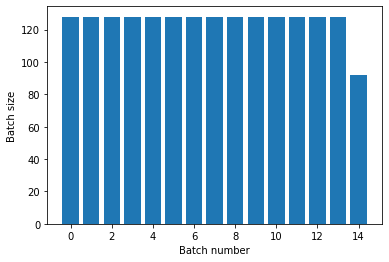
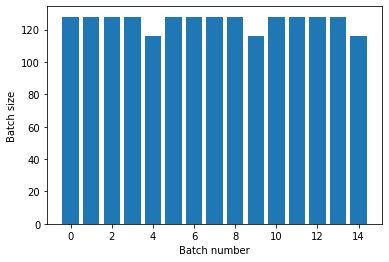
titanic_batches = titanic_lines.batch(128).repeat(3)
plot_batch_sizes(titanic_batches)
- Randomly shuffling input data
The Dataset.shuffle() transformation maintains a fixed-size buffer and chooses the next element uniformly at random from that buffer
2.3 预处理数据
The Dataset.map(f) transformation produces a new dataset by applying a given function f to each element of the input dataset.
use the tf.py_function() operation in a Dataset.map() transformation to call python libraries.
2.4 resampling
参考:https://tensorflow.google.cn/guide/data?hl=zh-cn#consuming_tfrecord_data