2-2-xyz2grd、surface和nearneighbor算法剖析
xyz2grd、surface和nearneighbor三个模块的用法参考:grd文件的生成–网格化
nearneighbor -I2m -S5m -V %inf% -Gtmp.grd -R90/100/35/40
To create a gridded data set from the file seaMARCII_bathy.lon_lat_z
using a 0.5 min grid, a 5 km search radius, using an octant search, and set
empty nodes to -9999:
nearneighbor seaMARCII_bathy.lon_lat_z -R242/244/-22/-20 -I0.5m -E-
9999 -Gbathymetry.grd -S5k -N8
-S: Sets the search_radius in same units as the grid spacing
-N: The circular area centered on each node is divided into sectors
sectors. Average values will only be computed if there is at least one value
inside at least min_sectors of the sectors for a given node
只使用了相邻的值给不同的权重系数计算网格上的点;
surface out1.dat -Gout1.grd -R116/118/31/35 -I0.001/0.001
-T<tension>[i][b]:添加tension到网格化方程,tension 取值范围为[0,1]。默认取0,给出最小曲率解;取1给出harmonic spline解。对于位场数据可以取0.25或稍大是较好的,对于topography取0.75较好。
surface算法来源:Smith, W. H. F., and P. Wessel, Gridding with continuous curvature splines in tension, Geophysics, vol. 55 (3), pp. 293-305, 1990..
以上两种都是对不同间隔的数据做网格化
而xyz2grd是对等间隔数据做网格化。
在GMT的很多命令中都会涉及到格网文件,在上一节中已经较为详细的介绍了格网文件的相关内容。本章将详细介绍如何生成格网文件。
在我们所获取的数据里,通常都是(x,y,z)形式,而这些数据有的已经是按规则的格网排列好的,而大多数都是不规则分布的数据形式。对于按规则格网排列好的(x,y,z)数据,只需用xyz2grd命令即可生成格网文件;对于不规则分布或者随意分布的数据,首先需要将这些数据进行格网化,生成按规则格网排列的(x,y,z)数据,然后再转化为格网数据。这里主要讨论随意分布的数据如何格网化并生成格网数据。 数据格网化,常用有两种算法:nearest neighbor gridding和gridding with splines in tenson
-
nearest neighbor gridding 该方法对应的GMT命令为nearneighbor,该命令的详细用法这里不做介绍,只讲述这种格网化算法。 nearneighbor命令将会指定数据范围和格网间隔,从而即可确定格网结点。此外,该命令还需要给出搜索半径,-Sradius选项。有了结点,有了搜索半径,即可搜索出该结点附近分布的点值了,根据这些点值,利用距离做权重,计算出结点处的值,即为格网点的值了。该算法要求在每个结点的搜索范围内只要有一个点,如果没有点,则该结点值被设为NaN值。
例:nearneighbor –R245/255/20/30 –I5m –S40k –Gship.nc –V ship.xyz 注:当数据较密时,适合用该方法。 -
gridding with spline in tension 利用全局的数据进行格网化。具体说来就是,将所有的数据投影到一个surface上,surface上对应的格网点值就是格网值。因此,相比这两种方法,nearneighbor是利用局部范围的数据进行格网化,而该方法是用全局的数据进行格网化。
在利用全局的数据进行格网化之前,为了消除aliasing效应,需要用blockmean或blockmedian或blockmode命令对数据进行预处理。blockmean命令适用于较为平滑的数据;blockmedian适用于起伏较大的数据。预处理后的数据,即可用surface命令进行格网化并生成格网数据了。
例:blockmean –R245/255/20/30 –I5m –V ship.xyz > ship_5m.xyz surface ship_5m.xyz –R245/255/20/30 –I5m –Gship.nc –V
注:相同的数据,surface和nearneighbor命令格网化的结果差别较大。
此外,GMT还提供了两个格网数据提取和信息查询的命令,分别是grdraster和grdinfo,这里就不在详细介绍了。
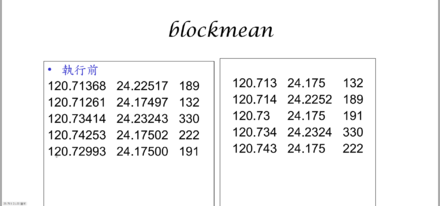
- surface预处理 GMT 提供了 3 种预处理的方法,分别为命令blockmean 、blockmedian 和 blockmode。第一个命令对网格间隔框内的值取平均值,第二个命令返回中值,后一个命令返回众值。作为一般规律,我们对于大多数平滑数据(比如位场 potential fields )采用平均数,而对于比较粗略的,非高斯数据(比如地形数据)采用中值或众值。 除了要求的–R 和 –I 转换开关外,这些预处理采用同样的选项: